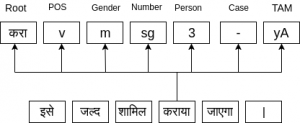
 The project aims at predicting: Parts-of-speech (POS), Gender (G), Number (N), Person (P), Case (C), Tense-aspect-mood (TAM) marker as well as the Lemma (L) or roots of words occurring in Hindustani texts (viz. Hindi and Urdu), by sharing the knowledge learned while capturing the representation of each of these in a multi-task learning framework. Further, we also take into account sets of task-specific phonetic features optimized through multi-objective GAs to achieve improved performance. To read more, please check my git repo as well as the arXiv preprint.
The project aims at predicting: Parts-of-speech (POS), Gender (G), Number (N), Person (P), Case (C), Tense-aspect-mood (TAM) marker as well as the Lemma (L) or roots of words occurring in Hindustani texts (viz. Hindi and Urdu), by sharing the knowledge learned while capturing the representation of each of these in a multi-task learning framework. Further, we also take into account sets of task-specific phonetic features optimized through multi-objective GAs to achieve improved performance. To read more, please check my git repo as well as the arXiv preprint.